A flaw in the Google Cloud Vertex AI SDK for Python let an attacker with no access to a victim’s project hijack the victim’s machine learning model upload and run code inside Google’s serving infrastructure.
Palo Alto Networks Unit 42, which found and reported the bug through Google’s bug bounty program, calls the technique “Pickle in the Middle” and said it saw no exploitation in the wild. Google has patched it; if you use the SDK, update to version 1.148.0 or later.
The attacker needed only a Google Cloud project of their own and the victim’s project ID, which is often public. No credentials, no phishing, no foothold in the target.
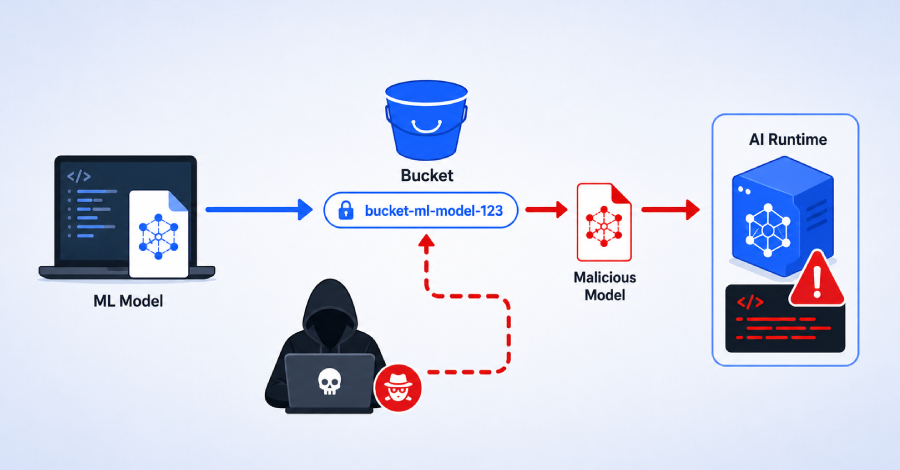
The flaw was in how the SDK chose a temporary Cloud Storage bucket for model uploads. If a user did not set a bucket, the SDK generated a predictable name from the project ID and region, such as project-vertex-staging-region. It checked whether that bucket existed, but not whether the victim owned it.
Because bucket names are globally unique, an attacker could create the expected bucket first in their own project. The victim’s SDK would then upload the model files to the attacker’s bucket. The attacker could then replace the uploaded model with a malicious one.
Many Python ML models are saved with pickle or joblib, which can run code when a file is loaded. When Vertex AI later loaded the swapped model, the attacker’s code executed inside the serving container.
The attack depended on speed. Unit 42 measured about 2.5 seconds between the victim’s upload and Vertex AI reading the file. In its proof of concept, the attacker used a Cloud Function that triggered after upload and replaced the model in 1.4 seconds, before Vertex AI read it.
The payload then stole an OAuth token from the serving container’s metadata server and sent it to the attacker. In Unit 42’s test environment, that token was not limited to the compromised deployment. It could access other model artifacts in the same Google-managed tenant project, including a full TensorFlow model with trained weights, as well as BigQuery metadata, access lists, tenant logs, GKE cluster names, and internal container image paths.
The attack worked only under specific conditions: the victim’s default staging bucket did not already exist in that region, and the victim left the staging_bucket parameter unset. The first is common for a new project in Vertex AI in a region.
The second depends on the developer relying on the SDK’s default rather than naming their own bucket.
Unit 42 reported the flaw through Google’s Vulnerability Reward Program on March 5, 2026. It tested versions 1.139.0 and 1.140.0, the latest available at the time, and found both vulnerable.
Google shipped an initial fix in v1.144.0 on March 31, adding a random uuid4 to the bucket name. It completed the fix in v1.148.0 on April 15, adding bucket ownership verification to block bucket squatting in Model.upload(). As of publication, neither Unit 42 nor Google’s Vertex AI security bulletins list a CVE for the issue.
Update to 1.148.0 or later so the ownership check is active. Also, set an explicit staging_bucket to a Cloud Storage location you control when uploading models. Because the flawed logic lives in the client SDK, check the google-cloud-aiplatform version wherever it runs, including notebooks, CI jobs, and training pipelines, not only production services.
It is the second predictable-bucket-name flaw to surface in Vertex AI this year. Google patched CVE-2026-2473 in February, a separate bucket-squatting bug in Vertex AI Experiments that also allowed cross-tenant code execution, model theft, and poisoning.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


Leave a Reply